Gerd Gigerenzer’s fast-and-frugal heuristics are simple, efficient mental shortcuts (rules of thumb) that help people make quick, good-enough decisions with limited information, time, and computational power. This is radically different from the more conventional belief that complex calculations always yield better results.
Giverenzer’s “adaptive toolbox” identifies and relies on evolved psychological capacities to exploit environmental structures.
“Context matters:” and it matters most when we confront un-kind envirornments with bounded rationality and where speed and simplicity are the focus. Under these, commonplace, circumstances, Gigerenzer’s heuristics outperform complex models.
Examples of these adaptive toolbox heuristics are “Take-the-Best.” In take-the-best an analyst stops at the first useful clue. The “Recognition Heuristic” where presented with two options where the analyst recognizes only one of the options then you choose the recognized one. Fast-and-Frugal Trees, are simple, sequential decision trees where questions are asked one question at a time. The sequence ends when a decision can be made. The “Tallying Heuristic” is another simple decision-making strategy where you count the number of features favoring one option over another. Each one of the features is ascribed equal importance. After the tallying is complete the analyst chooses the one with the most “votes.” Put differently, this is a weighted linear average where the weights are equal to 1. It is appealing because it ignores the routine trade-offs that naturally creep in when we appraise different baskets of features.
Modeling
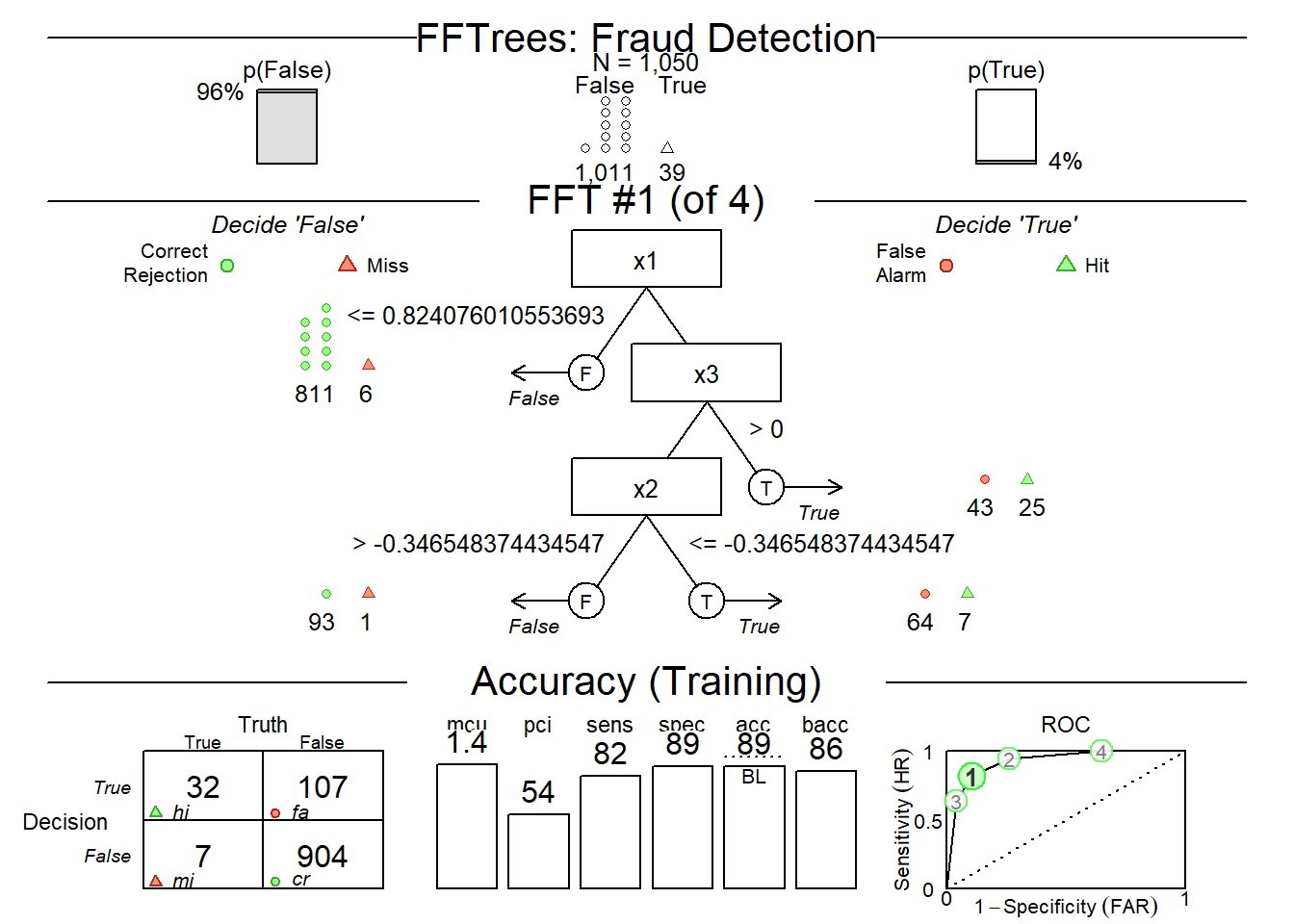
FFTrees and OneR are both R packages designed for creating simple, interpretable classification models, but they differ significantly in their methodology, structure, and complexity. FFTrees creates fast-and-frugal trees—hierarchical, non-compensatory, sequential decision trees. OneR creates a “One Rule” model—the simplest possible rule-based model that selects the single best predictor variable to classify data.
Methodology
This R script compares the FFTrees and OneR classification algorithms using the built-in breastcancer dataset. It evaluates both models based on accuracy and provides visualizations for each.
Generate synthetic data
Imbalanced sample
options(digits =3, scipen =9999)remove(list =ls())graphics.off()setwd("C:/Users/arodriguez/Dropbox/RPractice/tools")suppressPackageStartupMessages({suppressWarnings({library(tidyverse)library(ROSE)library(rsample)library(modeldata)library(probably)library(e1071)library(yardstick)library(pROC)library(rms)library(FFTrees)library(OneR)library(caret) })}) n =1500 fraud =rbinom(n, 1, prob =0.04) # 4% fraud prevalence x1 =rnorm(n, mean =0+2*fraud, sd =1) x2 =rnorm(n, mean =0-1*fraud, sd =1.5) x3 =rbinom(n, 1, prob =0.2+0.5*fraud) data <-data.frame(fraud = fraud, x1 = x1, x2 = x2, x3 = x3) data$myfraud =c(data$fraud ==1) data$fraud <-as.factor(data$fraud) data$myfraud <-as.factor(data$myfraud)# Split into training (70%) and testing (30%) setsset.seed(42) split =initial_split(data, prop =0.70) train_data <-training(split)test_data <-testing(split) head(data)
Call:
OneR.formula(formula = fraud ~ x1 + x2 + x3, data = train_data)
Rules:
If x1 = (-3.54,-2] then fraud = 0
If x1 = (-2,-0.469] then fraud = 0
If x1 = (-0.469,1.06] then fraud = 0
If x1 = (1.06,2.59] then fraud = 0
If x1 = (2.59,4.13] then fraud = 1
Accuracy:
1019 of 1050 instances classified correctly (97%)
summary(oner_model)
Call:
OneR.formula(formula = fraud ~ x1 + x2 + x3, data = train_data)
Rules:
If x1 = (-3.54,-2] then fraud = 0
If x1 = (-2,-0.469] then fraud = 0
If x1 = (-0.469,1.06] then fraud = 0
If x1 = (1.06,2.59] then fraud = 0
If x1 = (2.59,4.13] then fraud = 1
Accuracy:
1019 of 1050 instances classified correctly (97%)
Contingency table:
x1
fraud (-3.54,-2] (-2,-0.469] (-0.469,1.06] (1.06,2.59] (2.59,4.13] Sum
0 * 28 * 304 * 542 * 132 5 1011
1 0 0 10 16 * 13 39
Sum 28 304 552 148 18 1050
---
Maximum in each column: '*'
Pearson's Chi-squared test:
X-squared = 300, df = 4, p-value <0.0000000000000002
Key Considerations for Recall
Fraud: In unbalanced samples, Recall is often more critical than accuracy because it measures the model’s ability to identify all positive cases (minimizing false negatives).
FFTrees allows you to specifically optimize for high recall (minimizing misses) by choosing different tree growth algorithms (e.g., using the goal = "sens" argument in the FFTrees() function).
OneR Limitation: Since OneR uses only a single predictor, its recall is strictly tied to the distribution of that one variable and may be lower if the signal is spread across multiple features.